GPU Divergence in AMD CDNA 3 - StructurizeCFG Pass
Introduction
I've been exploring GPU divergence especially in AMD CDNA3 based GPUs (MI300x) and in this post, we will dive into how divergence is handled in CDNA-3 GPUs. When a wavefront diverges, we need to remember the state of the threads before the divergence, the diverging paths themselves (along with which thread takes which path) and finally the point of reconvergence. There are two approaches to this - Special hardware instructions that push/pop the required details from a special stack, or compiler-managed thread mask control. Interestingly, I found that CDNA-3 GPUs seem to rely on the compiler to handle divergence despite having special instructions to do so. Let us look at both approaches.
Two approaches - Software vs Hardware
Consider a simple control flow as follows
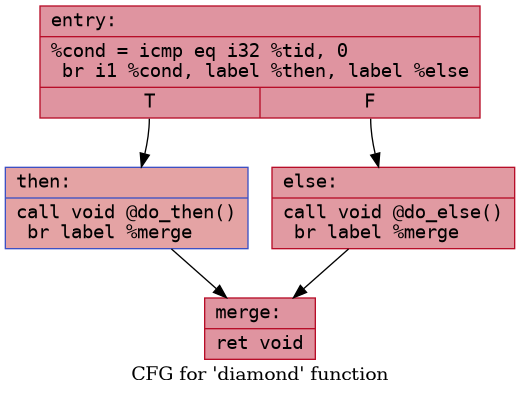
When a wavefront encounters the condition at the end of
entry block, it must save the current information about
active threads, disable all threads that meet the condition, and start
executing the false path. The hardware must also know when to stop
executing the false path and switch over to the true path. Finally, the
hardware must know how to restore the state of active threads as it was
before this region.
Hardware based approach
The AMD CDNA-3 ISA documents a hardware mechanism for handling
divergence using S_CBRANCH_I/G_FORK and
S_CBRANCH_JOIN instructions. These FORK/JOIN instructions
use a six-deep stack stored in SGPRs, with a Control Stack Pointer (CSP)
to track nesting depth.
When a wavefront encounters a FORK:
- It computes
mask_passandmask_failfrom the condition and current EXEC - If all threads go the same way (uniform branch), just jump
- If divergent, the path with fewer threads executes
first (EXEC = smaller group), and the other path's
{PC, EXEC mask}is pushed onto the SGPR stack. CSP is incremented
By always executing the smaller group first, the stack depth is bounded to log₂64 = 6 because at each nesting level, at max half the threads are executed.
When a path reaches JOIN:
- It compares the current CSP against the saved CSP value from when
the FORK started (passed via
arg0) - If they differ, all paths have not completed yet. CSP is
decremented, and
{PC, EXEC}is popped from the stack to begin executing the next path - If they match, all paths have completed. Execution continues past the JOIN
Each stack entry is 128 bits: {EXEC[63:0], PC[47:2]},
stored across 4 consecutive SGPRs. FORK/JOIN blocks can be nested to any
depth (limited only by SGPR availability), and can coexist with other
conditional flow control.
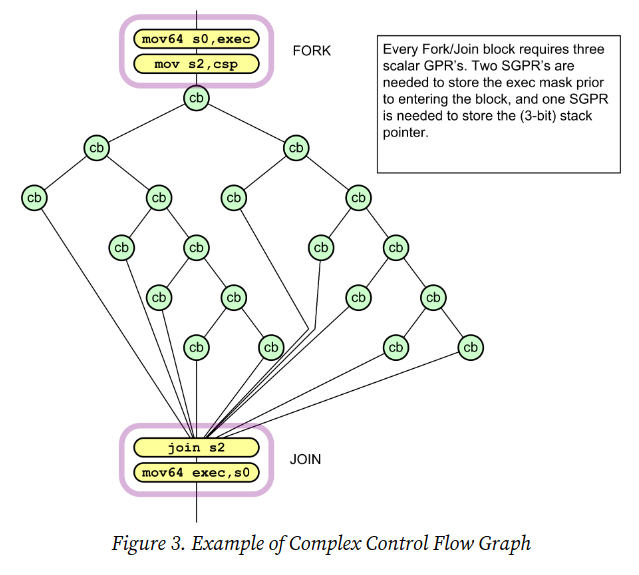
This brings us to the twist — these FORK/JOIN instructions are never emitted by the compiler. In all my experiments involving complicated and twisted control flows, I was never able to get the compiler to actually emit these instructions.
A brief comparison with NVIDIA
Let us also briefly take a look at what we know about divergence in
NVIDIA GPUs. NVIDIA GPUs (Volta and later) seem to take the hardware
approach. They use BSSY and BSYNC instructions
with convergence barrier registers (B0, B1,
...):
BSSY B0, <target>— Saves the current active thread mask into barrier register B0. Placed before a divergent branch.BSYNC B0— Reconvergence barrier. Threads arriving here are marked as "arrived" in B0. If all threads recorded in B0 have arrived, execution continues with the full mask restored. If not, the arriving threads are blocked and the hardware switches to execute the other path.
Here is the actual SASS generated by NVIDIA's compiler (Turing, sm_75) for a diamond (if-then-else) kernel:
1 | |
1 | |
The compiler inserts BSSY B0 before the divergent branch
to record which threads are active. Both paths converge at
BSYNC B0, where the hardware waits for all threads recorded
in B0 to arrive, then restores the full active mask and continues.
Unlike AMD's FORK/JOIN, NVIDIA's compiler actively uses these hardware
instructions.
Unfortunately, how exactly these instructions work on a microarchitecture level is not documented anywhere. I found one paper that attempts to reverse engineer and model it. Find it here - Control Flow Management in Modern GPUs.
Software (compiler) based approach
Since I couldn't get the compiler to emit any FORK/JOIN
instructions, it strongly suggests that the compiler is handling
divergence and reconvergence on its own. So how does it do it? By
directly flipping bits in the EXEC register. The EXEC
register is a 64 bit register, one bit for each thread, which controls
which thread is enabled/disabled (1/0) and the compiler approach to
handling divergent flow involves directly manipulating this
EXEC register.
Consider the following kernel:
1 | |
The corresponding control flow graph looks like this:
To handle divergence, the compiler must restructure (linearize) this
so that both True path and False path execute
sequentially with different EXEC masks applied. 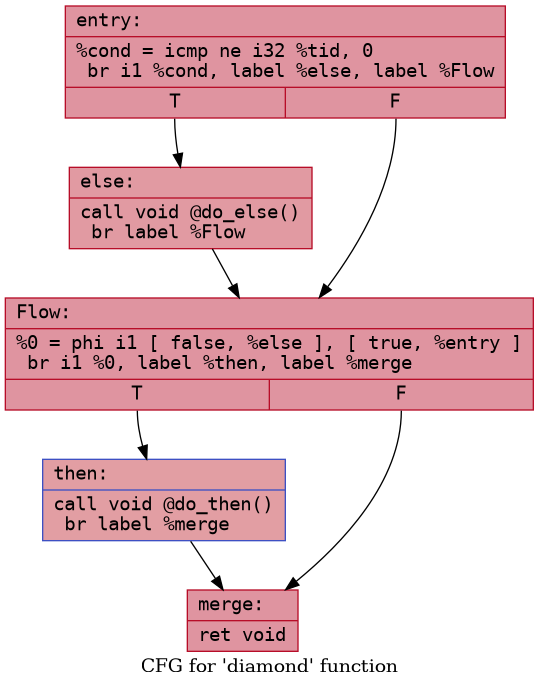
Now inserting the EXEC masking instructions becomes
straightforward.
- Save the
EXECregister at the end ofentryand mask it to only execute else path. - Execute the else path.
- At
Flowblock, flip theEXECregister bits enabling the other set of threads - Execute the
thenpath. - At merge restore the
EXECas it was at the end ofentry
At each condition, we also have the option of skipping a path if no
thread meets the condition. For example, at the end of entry, we can
directly jump to Flow block if no thread meets the
condition for the else block.
Here is the actual ISA generated by the compiler for gfx942 (MI300X):
1 | |
Note: I generated these examples by running the StructurizeCFG pass in isolation to avoid other optimizations altering the results.
The pass that handles this restructuring is the
StructurizeCFG pass. The core idea behind the pass is to
sequentialize the execution of all divergent paths by inserting
Flow blocks which act as merge/flip points from where
execution can safely switch to the sister path (by flipping the
EXEC mask). The pass must handle nested divergent branches
as well. This can be done by merging all appropriate threads before
flipping the EXEC register as seen below.
Now let us consider a slightly more complicated kernel:
1 | |
The corresponding control flow graph would look something like this:
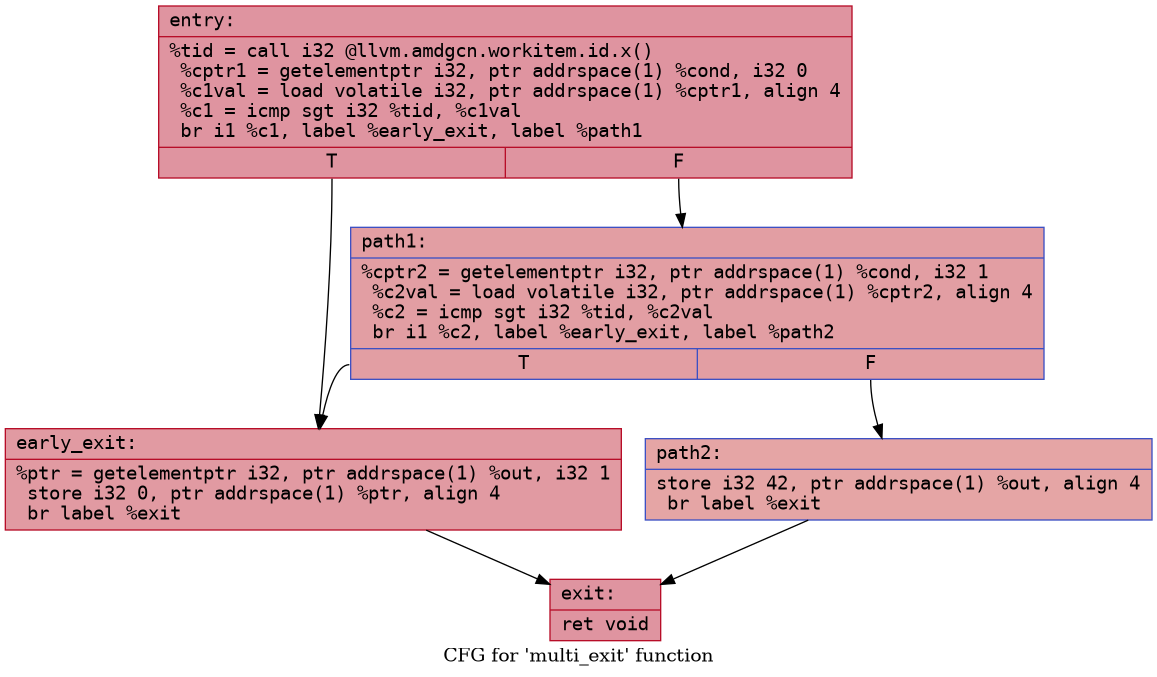
In this case, observe that early_exit block has two
predecessors. The exec mask will be saved at end of entry
block and then also at the end of path1. In
early_exit, depending on whether threads are arriving from
entry or from path1, the compiler needs to
emit different EXEC restore instruction. This is how the
compiler transforms the structure:
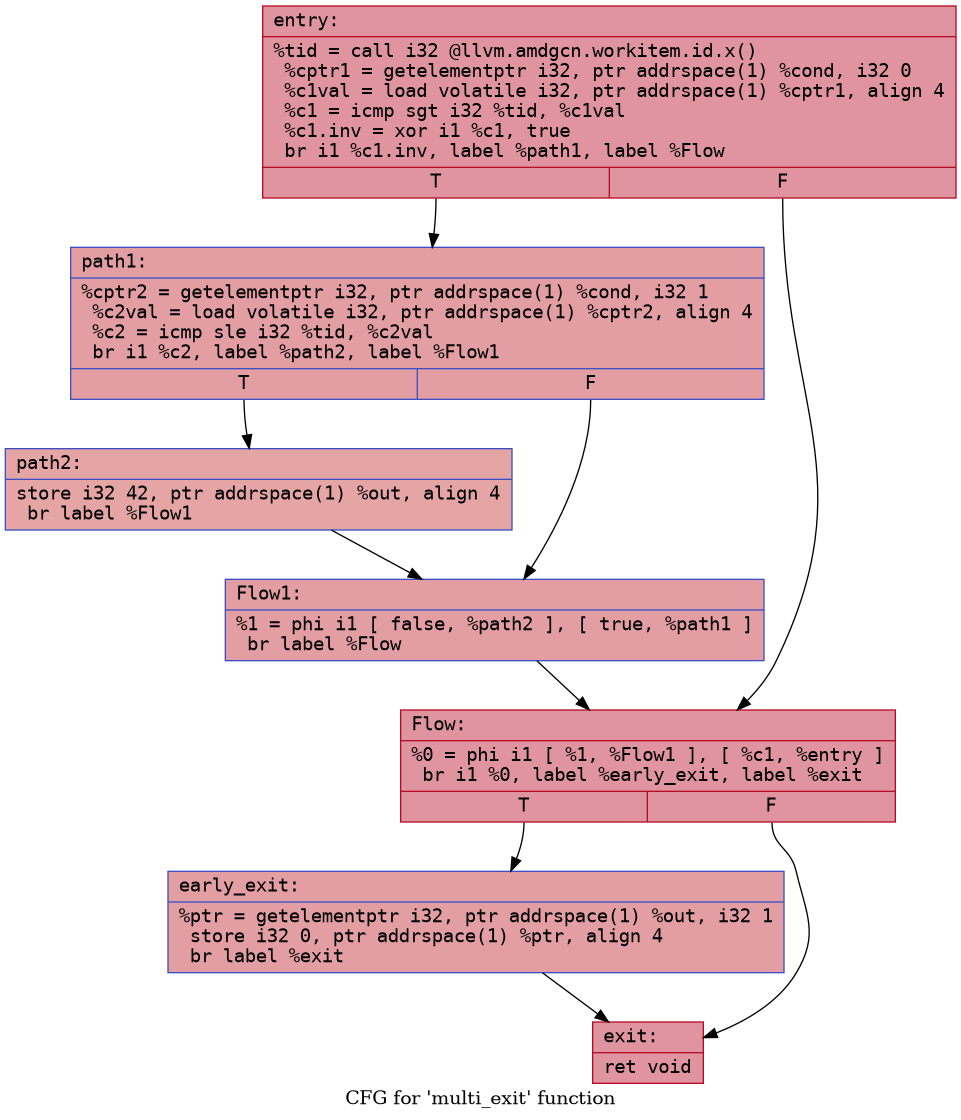
Now early_exit has a single predecessor
(Flow), and the EXEC operations become easier to insert
correctly:
- At
entry: compute the entry exit mask (tid > c1) and store it ins[4:5]. Save EXEC, restrict to path1 lanes (tid <= c1) - At
path1: save EXEC again, restrict to path2 lanes (tid <= c2) - Execute
path2 - At
Flow1: restore EXEC to path1 level. Merge the path1 exit mask intos[4:5]— nows[4:5]contains the combined mask of all threads that should go toearly_exit(from both entry and path1) - At
Flow: restore EXEC to entry level (all threads). Save EXEC, restrict to early_exit lanes usings[4:5]. Executeearly_exit
Here is the actual ISA generated by the compiler for gfx942 (MI300X). Let's trace through it with a concrete example: 8 threads, c1=3, c2=2.
- Threads 0-3:
tid <= c1, enter path1 - Threads 4-7:
tid > c1, should exit early - Threads 0-2:
tid <= c2, enter path2 - Thread 3:
tid > c2, should exit early from path1
Let's track the EXEC mask and key registers at each step (1 = active, 0 = masked off):
1 | |
Notice how the Flow1 block collects exit masks from
different nesting depths and merges them into s[4:5]. By
the time we reach Flow, s[4:5] = 1111 1000
which is exactly the threads that should exit early (thread 3 from
path1, threads 4-7 from entry). The save/restore pairs are nested
cleanly like parentheses: SAVE → SAVE → RESTORE → RESTORE → SAVE.
Conclusion
So CDNA-3 GPUs rely entirely on the compiler to handle divergent
control flow. The StructurizeCFG pass linearizes the CFG,
and the backend emits EXEC mask operations to sequence
through each path. This is despite the ISA manual documenting support
for hardware based divergence handling using the FORK/JOIN instructions.
I am not sure why the compiler doesn't generate these instructions but I
am planning on investigating further.